
Can DeepSeek Generate Images? Janus-Pro Tested (2026)

The Short Answer:
No – at least not in the app you're picturing. The DeepSeek chatbot runs language models: the current V4-Pro and V4-Flash flagships and the older R1. Type "draw me a cat" and you'll get a tidy paragraph about cats, not a cat. NVIDIA's own deployment doc for V4-Pro even lists its input type as text only, which tells you where the company's head is at with these models.
But here's the "but." DeepSeek the company does make an image model. It's called Janus-Pro, it's open-source and free, and you run it yourself – on Hugging Face or your own GPU. It isn't built into the chat app, and after a weekend with it, I understand why DeepSeek isn't putting it on a billboard.
So who is this actually for?
Use it if: you want a free, open-weight image model you can self-host and tinker with – handy for research or testing how faithfully a model follows a prompt – and you've got a capable GPU to throw at it.
Skip it if: you want clean, high-resolution images, faces that look like faces, or a one-click experience inside an app. ChatGPT, Gemini, and Midjourney are in a different league here, and I'll show you the gap below.
What DeepSeek Actually Is (V4-Pro, V4-Flash, R1 & Janus)

Most of the confusion comes from treating "DeepSeek" as one thing. It's two.
The first line is the language models – the stuff that made DeepSeek a household name. There's V3, then the R1 reasoning model from early 2025, and now the V4 series from April 2026: V4-Pro, a 1.6-trillion-parameter Mixture-of-Experts model with a million-token context window, and the lighter, cheaper V4-Flash. These are text in, text out. Excellent at reasoning and code. Hopeless at drawing.
The second line is Janus – a research family of "unified multimodal" models. Janus-Pro, released in January 2025, is the one that can actually make pictures. Picture a car company that builds a famous sedan and, off in a separate skunkworks lab, a concept bike. Same badge, completely different product – and you can't buy the bike at the sedan dealership.
There was a wrinkle, too. Before V4 launched, the Financial Times reported that the new model would add image and video generation. The version that actually shipped is text, reasoning, and agentic coding – no native image generation in sight. So if that headline got you excited, I understand. It just didn't pan out.
Can the DeepSeek App or Website Generate Images?
No. I tried, repeatedly, because I didn't want to take a spec sheet's word for it.
In the official app and on chat.deepseek.com, asking for an image gets you a polite refusal – some flavor of "I can't generate images." Third-party guides that map out DeepSeek's entire model lineup say the same thing: the chat products don't do images, and they point you to Janus instead. Every so often a hopeful App Store changelog or forum post hints that in-chat images are coming, but nothing functional has actually landed in the app as I write this. Treat it as a rumor, not a feature. If you're weighing other chat assistants on this, I ran the same question for Perplexity and landed in a similar place.
Can DeepSeek R1 Generate Images?
Also no. R1 is a text-only reasoning model, and at this point it's essentially legacy – V4 has taken its place. R1 is the model you reach for when you need logic, math, or code reasoned through out loud. It is not the model you reach for when you need a logo. No hidden image mode, no secret command. Text in, text out.
Meet Janus-Pro: DeepSeek's Actual Image Generator
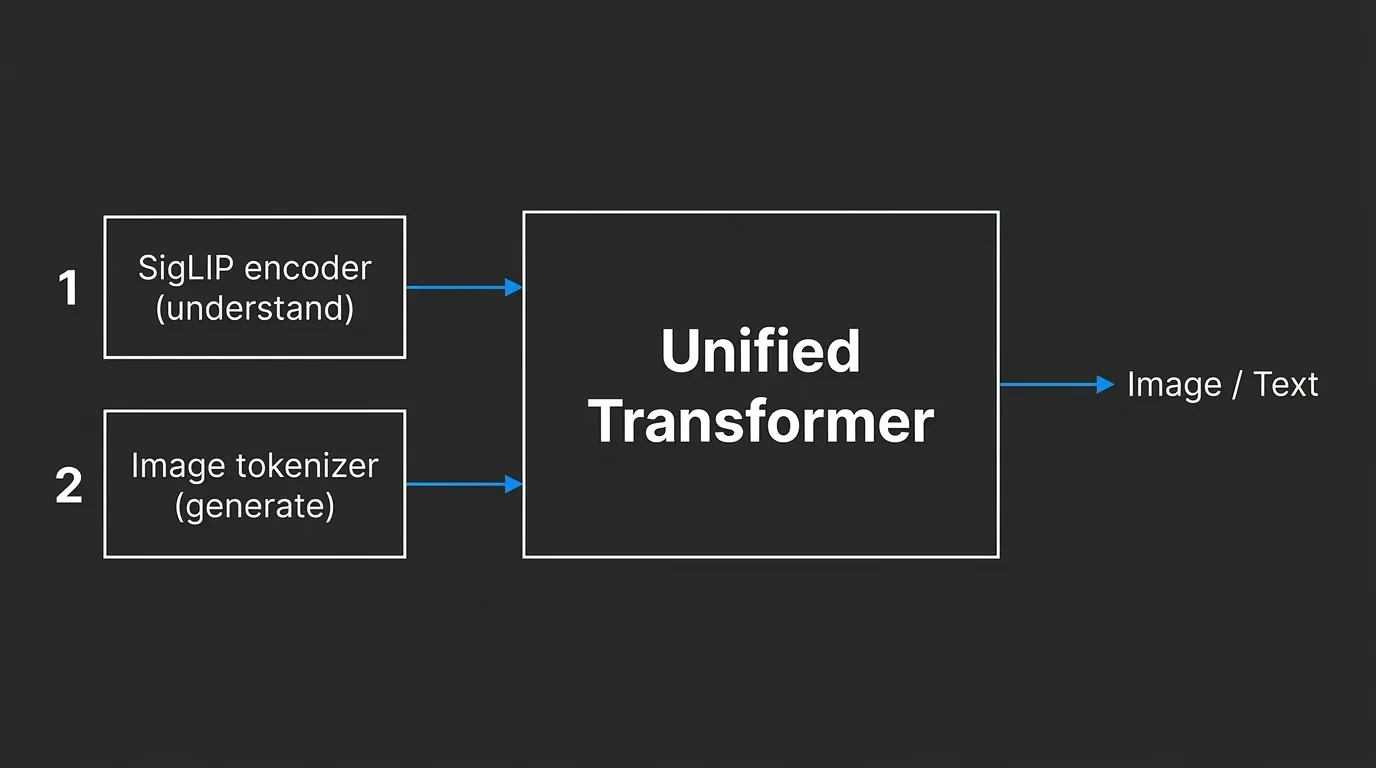
Janus-Pro comes in two sizes, 1B and 7B. The interesting part is the architecture. Instead of forcing one vision system to both understand and create images, Janus-Pro splits the job: a SigLIP encoder handles "looking at" images, a separate tokenizer handles "drawing" them, and both feed a single transformer built on DeepSeek's own LLMs. Decoupling those two roles is the entire pitch, and on paper it works.
On the benchmark DeepSeek likes to quote – GenEval – Janus-Pro-7B scores 0.80, ahead of DALL·E 3 at 0.67 and Stable Diffusion 3 Medium at 0.74. Sounds like a giant-killer, right?
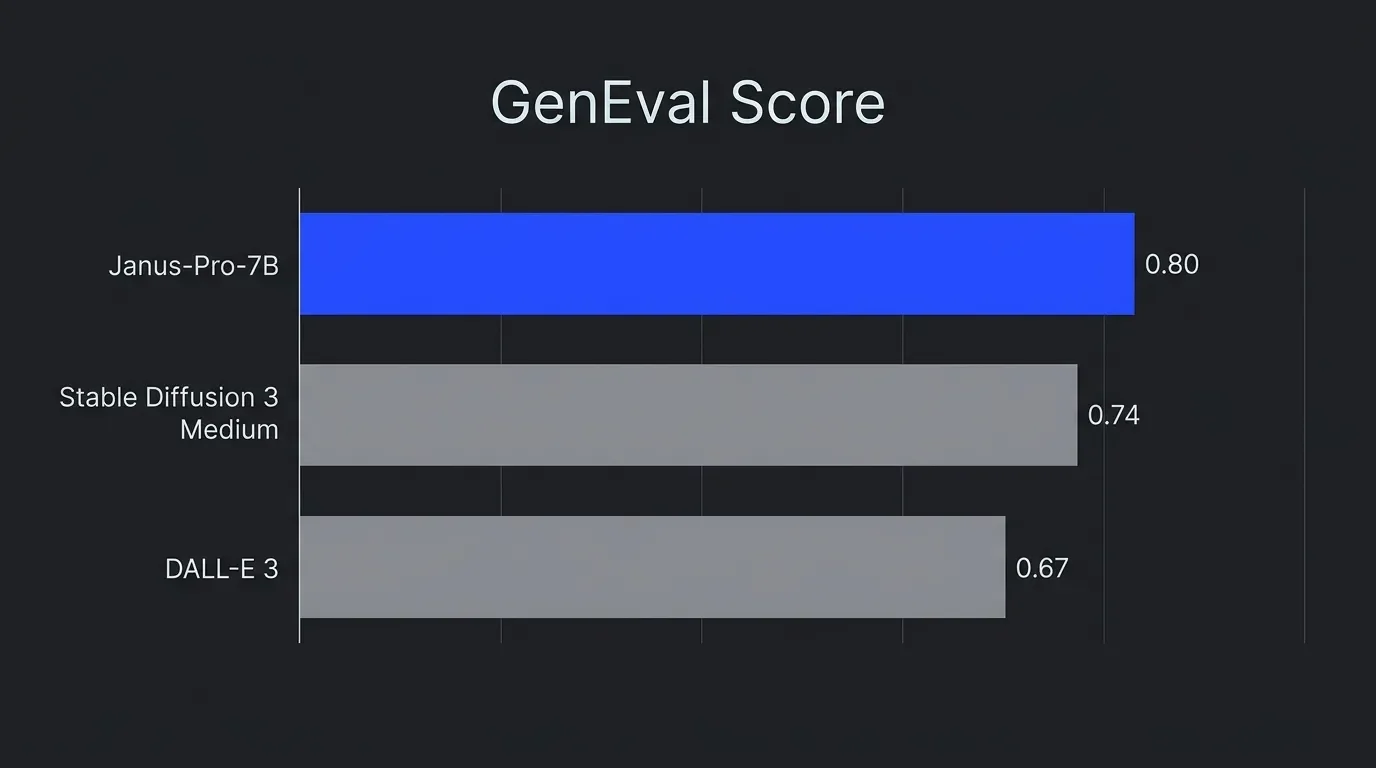
Well, here's the catch – and I kid you not – it's a big one. GenEval measures prompt adherence – did the model include the three red apples and the blue cup you asked for – not whether the result actually looks good. As one independent tester put it after a side-by-side run, most of what it generates is "hot garbage." Blunt. But my own results weren't far off. The other ceiling: output is locked at 384×384 pixels. That's all you get. The paper itself flags fine detail, human faces, and text as weak spots. So Janus-Pro is technically clever and practically limited, at the same time.
Quick note: a benchmark win for following the prompt is not the same as a win for image quality. That single distinction explains almost every disappointed Janus-Pro review you'll read.
How to Generate Images with DeepSeek (Janus-Pro), Step by Step
Three realistic ways to actually use it:
Hosted Demo (No Setup)
Open the Janus-Pro Hugging Face page and use a linked Space. One heads-up: the official Space was throwing a runtime error when I checked in June 2026, so you may need a community-hosted Space instead. "Just try it online" is less dependable than I'd like.
Run It Locally
Clone the repo (git clone https://github.com/deepseek-ai/Janus.git), install the dependencies, and launch the Gradio demo or the generation script (setup guide here). Hardware warning: even a 24GB RTX 4090 can feel tight at 384×384, per one hands-on writeup – and that lined up with what I saw: even my 16” MacBook Pro (M1 Max) with 64GB unified memory struggled with it.
In the Browser (1B Only)
The smaller 1B model has been shown running fully client-side on WebGPU. Lower quality than the 7B, but genuinely zero install.
The one thing you can't do is crank the resolution. It's hard-coded to 384×384, and users (myself included) have confirmed there's no reliable way to raise it.
DeepSeek vs ChatGPT, Gemini & Midjourney for Images
Here's the honest lay of the land if you just want a picture made:
| Tool | In-App Image Generation | Image Model | Independent Quality View | Access | Cost | NSFW Stance |
|---|---|---|---|---|---|---|
| DeepSeek (Janus-Pro) | No – separate model, not in app/API | Janus-Pro 1B / 7B, 384×384 | Strong prompt adherence, weak detail and faces | Hugging Face / local / third-party | Free, open-weight (you pay for compute) | No stated policy; runs unfiltered locally |
| ChatGPT | Yes | GPT Image (DALL·E lineage) | Rated highly in informal tests | Web / app / API | Free tier; Go $8/mo; Plus $20/mo; Pro from $100/mo | Strict content filter |
| Gemini | Yes | Nano Banana Pro / Imagen 4 | Strong, current-generation quality | Web / app / API | Free tier; AI Pro ~$19.99/mo | Strict content filter |
| Midjourney | Yes (Discord/web) | Midjourney V8.1 | Top-tier aesthetics | Discord / web | From $10/mo, no free tier | Filtered; no explicit NSFW |
Note: Competitor prices move fast – double-check before you rely on them.
The short read: if image quality is the goal, DeepSeek isn't really competing in this row. It's the only free, self-hostable option on the list, and for some people that's the whole point. For everyone else, the paid tools win on output.
Can DeepSeek Generate NSFW Images?
Honest answer: I couldn't find any official policy for Janus-Pro. Because the weights are open and you can run them locally, there's no cloud filter standing between you and the model the way there is with ChatGPT or Gemini. In theory, that means fewer guardrails. In practice, two things get in the way. I couldn't find any widely used uncensored finetunes, and the model is so shaky at human anatomy and faces that it's a poor tool for that use even if you tried. "Technically unfiltered, practically bad at it" is where I land. If your platform or local laws care about this, don't assume – verify for yourself.
My Experience Testing DeepSeek Image Generation
I went in genuinely curious. I make thumbnails for my YouTube channels and hero images for this blog, so a free image model that beats DALL·E on a benchmark had my attention.
The online route fell over first. The official Hugging Face Space was erroring out, so I bounced to a community Space, then gave up and ran the 7B on a rented cloud GPU – RunPod, in my case – rather than tie up my own machine for an afternoon. Setup wasn't bad if you've cloned a repo before. If you haven't, this is not your starting point.
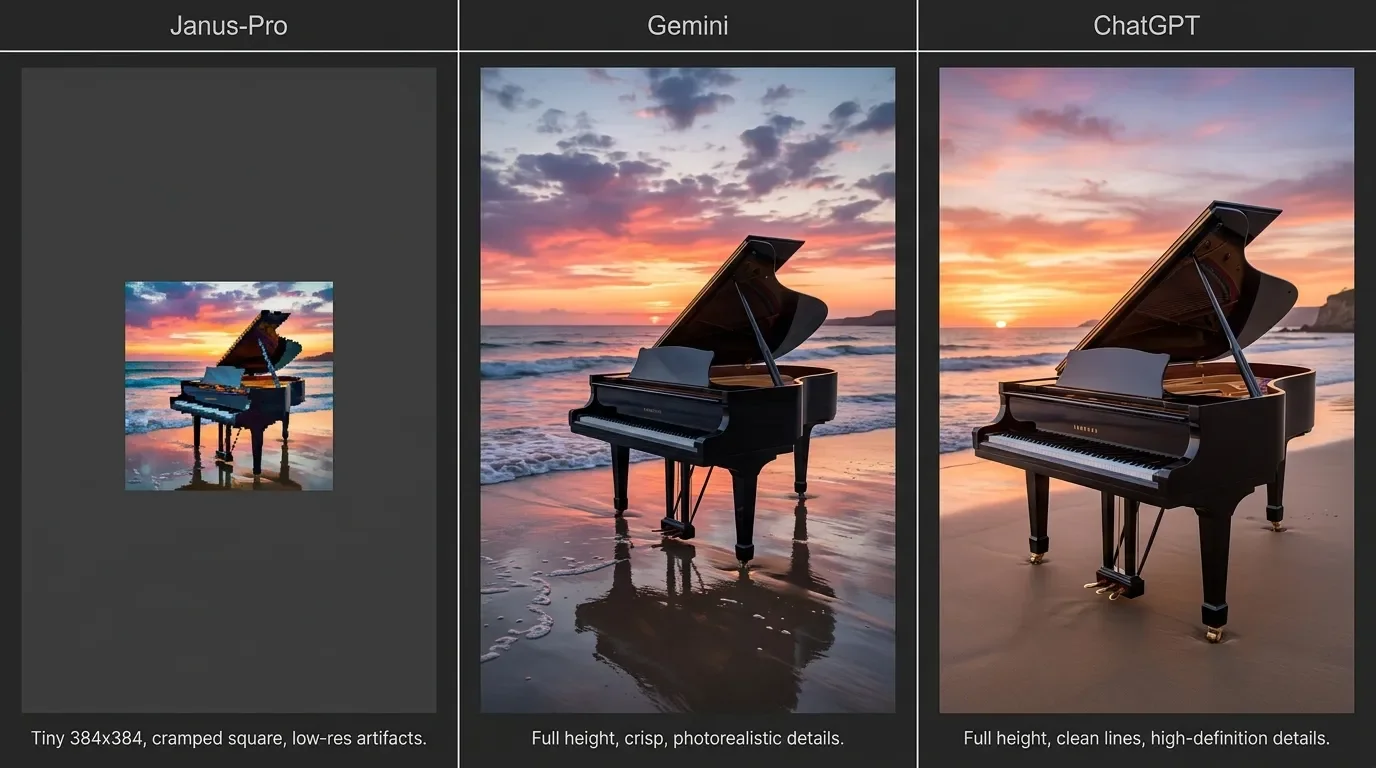
Then I started prompting. And here's the thing – the prompt adherence is real. When I asked for "a grand piano on a beach at sunset, sheet music scattered on the sand," it put all of that in the frame. Piano, beach, sunset, scattered paper. Genuinely impressive that a free model nailed the brief.
The problem was everything else. At 384×384 the image was tiny, and the moment a human crept into the frame it fell apart – melted faces, hands from a horror film, text that looked like a language I don't speak. I tried a simple portrait-style thumbnail and it was unusable. Not "needs a touch-up" unusable. "Start over in another tool" unusable. The same prompts in Gemini and ChatGPT gave me something I could actually drop into a thumbnail with light edits, at a real resolution. That's the gap that benchmarks hide.
Would I use it for real work? No. For poking at how these unified models behave, or as a free way to learn prompt engineering without burning credits? Sure. As my coffee-break verdict: a fascinating research toy, not a production tool.
Verdict: Should You Use DeepSeek for Image Generation?
So, can DeepSeek generate images? The chat app and R1 can't, full stop. The company's open-source Janus-Pro can – with serious strings attached: 384×384 output, weak faces, no turnkey app, and a GPU bill if you self-host.
Get it if you're a tinkerer or researcher who values "free and open" over "polished," and you enjoy running things yourself. If that itch is real, Hands-On Generative AI with Transformers and Diffusion Models is a solid grounding in how these multimodal models actually work under the hood. Avoid it if you just want a good picture with minimal fuss – pay for ChatGPT, Gemini, or Midjourney and move on with your day. For my own workflow, I'm sticking with the paid tools and keeping Janus-Pro in the experiments folder.
If you want the bigger picture on where DeepSeek's text models actually shine, that's a separate story.
Have you actually gotten something usable out of Janus-Pro, or did your faces melt like mine? Tell me what you ran it on and what you got in the comments below – I'd genuinely love to be proven wrong on the quality.
And if you want the next one of these – plain-English, hands-on tests of AI tools before you blow a weekend on them – you can subscribe to my tech newsletter.











FAQ
-
Yes. Janus-Pro is open-weight and free; the only thing you pay for is the compute you run it on. The DeepSeek chat app, on the other hand, doesn't generate images at all, free or paid. So "free" comes with the asterisk that you're the one hosting it.
-
A fixed 384×384 pixels, with no reliable way to push it higher. That's small by today's standards, and it's the main reason the images feel dated the second you need any real detail. In my testing it was the single biggest dealbreaker for thumbnails.
-
Officially, no – the deployment docs list V4-Pro as text-only input, and that's what I'd trust. A few secondary blogs claim native vision, but people poking at the actual API haven't found an image endpoint. Until DeepSeek documents it properly, treat vision support as unconfirmed.
-
On one specific benchmark, yes; in real use, no. Janus-Pro-7B beats DALL·E 3 on GenEval prompt adherence (0.80 vs 0.67), but that only measures whether the model includes what you asked for, not whether the picture looks good. As I covered above, the actual output quality isn't close.
-
For the 7B model, a strong GPU – even a 24GB RTX 4090 can feel tight at 384×384. The smaller 1B model is far more forgiving and has been shown running entirely in-browser on WebGPU. If you don't have the hardware, a rented cloud GPU like RunPod is the route I'd point you to.
-
Nothing has been announced. Janus-Pro (January 2025) is still DeepSeek's latest dedicated image model, and the image features rumored for V4 never shipped. I wouldn't hold my breath, but DeepSeek has surprised people before, so I won't rule it out either.
-
Probably, but read the license first. The code is MIT, and the repo says commercial use is permitted under the DeepSeek Model License, yet the Hugging Face card tags it simply "MIT" – a contradiction worth resolving before you ship anything client-facing. When money is involved, check the actual terms rather than trusting a summary.











